
A. CLEANING & TRANSFORMING DATA
Agenda
-
5 principles of data integrity.
- “Slogan”: high-quality dataset yield high-quality insights.
- Validity:
- A valid data follows “constraints” on uniqueness. (Dữ liệu hợp lệ tuân theo “các ràng buộc” về tính duy nhất.)
- Types of constraints: range constraints (out of range error), datatype constraints
- Accuracy:
- Accurate data matches a known source of truth. (Dữ liệu chính xác khớp với một nguồn sự thật đã biết.)
-
Completeness: accuracy & completeness is hard to achieve, meaning this truth is just a sub-part of the truth. Sometimes, our derived insights can be just an “overfitting” in machine learning.
- Consitency: same information shared among dataset should be the same.
-
Uniformity: data should use the same “unit measure” in all dataset.
- Dataset shape: number of rowns x number of coloumns
- Dataset skew: refer to the distribution of values:
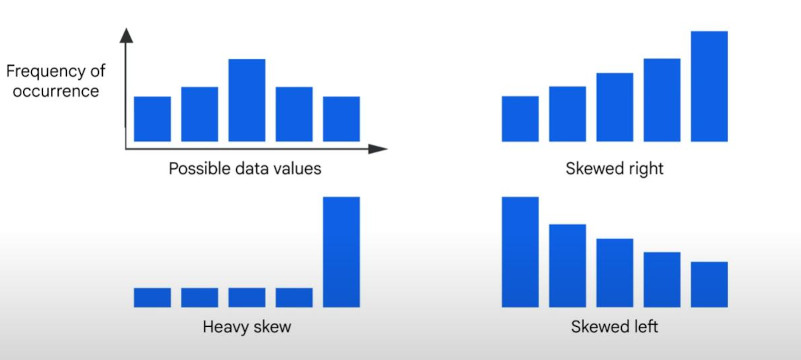
- Clean and transform data using SQL.
- Create test cases to check values.
- Look up values against an objective.
- IN(): for look up values
- Checking the shape and skew of dataset.
- NULLIF()
- IFNULL()
- COALESCE()
- Store one fact in one place and use IDs to look up.
- Helpful string functions to clean data
- PARSE_DATE()
- SUBSTR()
- REPLACE()
- Document and Comment your approach.
- Use FORMAT() to clearly indicate units.
- CAST() data types to the same format and digits.
- DATE(), TIME(), DATETIME() all accepts a timezone parameter.
-
Convert unix epoch values using TIMESTAMP_MICROS(), TIMESTAMP_MILLIS(), TIMESTAMP_SECONDS().
- WARNING : NULL is not ‘’

- Clean and transform data: other options.
- Slogan: use the right tool for the right job.
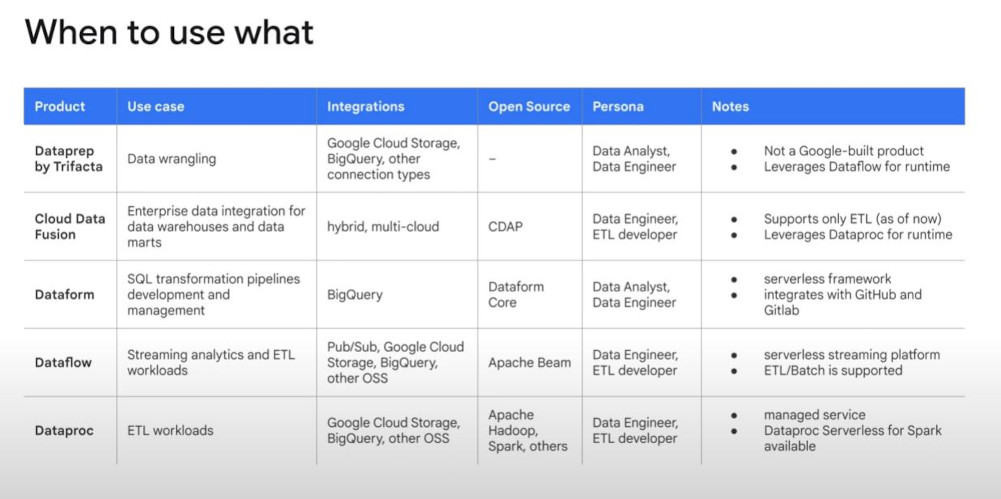
- “Cloud Dataprep”: built by Trifacta for data preparation. It’s a visual tool running on Dataflow. More info: “dataprep”
- “Cloud Data Fusion”: a fully-managed, cloud native, enterprise data integration service for quicly building & managing “data-pipeline”. It has no code and a great UI-based tool.
- “Wrangler” is a code-free, visual environment for transforming data into data pipeline. It can give you a TRY on a small sub-data before total application.
- Dataflow: a GC service to create a pipeline to process data. (extract, transform, loading = ETL)
- “Apache Beam” is an “open source” unified programming model to define both batch and streaming data-processing pipelines used by Dataflow.
- “Dataflow” is one of runners available in Beam.
-
Dataproc: make Hadoop and Spark workloads simple on Google Cloud. It’s integrated inside GC services such as BigQuery, Cloud Storage, Cloud BigTable, Cloud Logging, Cloud Monitoring.
- WHEN TO USE THEM
B. INGESING AND STORING NEW BIGQUERY DATASETS.
Agenda
- Permanent versus temporary data
- Way1: button “SAVE RESULTS” => select “BigQuery Table” type.
- Way2: use a virtual table called “View”, click btn “SAVE” (next to btn “RUN”) => select “SAVE VIEW”.
- “View” can be used for API, Looker or Looker Studio.
- “View” can be also created by SQL:

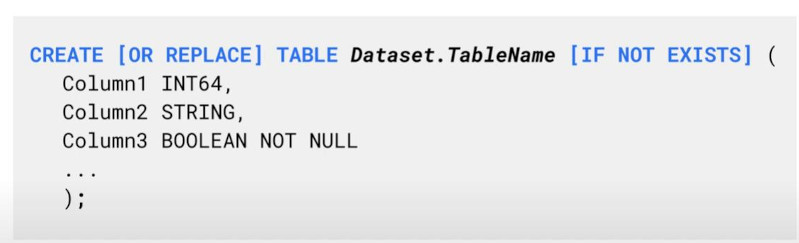
- Others: create a schema in BigQuery
-
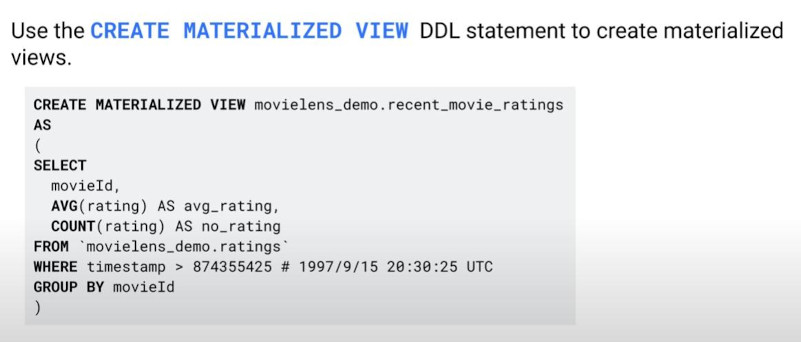
- “materialized_view”: lies on cache to increase performance. It reads only delta changes from the base table to update. Queries on “materialized_view” is faster than “base table”. “materialized_view” is auto-refreshed within 5 minutes of a change to the base table. (but no more frequently than every 30 minutes.)
- “materialized_view” can be created by SQL:
- LAB (1 credit): Creating Permanent Tables and Access-Controlled Views in BigQuery
- Task 1. Create a new dataset to store the tables
- Task 2. Troubleshooting CREATE TABLE statements
-
5 rules as creating a table:
-
rule1: Either the specified column list or inferred columns from a query_statement (or both) must be present.
-
rule2: When both the column list and “the AS query_statement clause” are present, BigQuery ignores the names in “the AS query_statement clause” and matches the columns with the column list by position.
-
rule3: When “the AS query_statement clause” is present and the column list is absent, BigQuery determines the column names and types from “the as query_statement clause”.
-
rule4: Column names must be specified either through the column list or “as query_statement clause”.
-
rule5: Duplicate column names are not allowed.
-
- Questions: What if the upstream raw data table
data-to-insights.ecommerce.all_sessions_rawwas updated with new transactions for 20170801? Would those be reflected in yourrevenue_transactions_20170801table? => NO, it’s not auto-reflected. - There are 2 solutions:
- Solution1: Periodically refresh the permanent tables. This can be done by 2 services, either by “BigQuery” => “Data Transfer” OR by CloudDataflow
- Solution2: Use “views” to re-run a stored query each time the view is selected.
- Task 3. Creating views (names start with “vw_” or “view_”)
- CREATE OR REPLACE VIEW… :
- CREATE VIEW IF NOT EXISTS… :
- Extras:
- SESSION_USER() : a func to call session-logined-email:
-
#standardSQL SELECT SESSION_USER() AS viewer; - how to set some permission in SQL:
-
WHERE REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') IN ('qwiklabs.net') -
We can see if session-loginned-email does not have domain “qwiklabs.net”, can only see the table, otherwise the table shows nothing.
- Add expiration for a “view”:
-
#standardSQL CREATE OR REPLACE VIEW ecommerce.vw_large_transactions OPTIONS( description="large transactions for review", labels=[('org_unit','loss_prevention')], expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 90 DAY) ) AS #standardSQL SELECT DISTINCT SESSION_USER() AS viewer_ldap, REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') AS domain, date, fullVisitorId, visitId, channelGrouping, totalTransactionRevenue / 1000000 AS totalTransactionRevenue, currencyCode, STRING_AGG(DISTINCT v2ProductName ORDER BY v2ProductName LIMIT 10) AS products_ordered FROM `data-to-insights.ecommerce.all_sessions_raw` WHERE (totalTransactionRevenue / 1000000) > 1000 AND currencyCode = 'USD' AND REGEXP_EXTRACT(SESSION_USER(), r'@(.+)') IN ('qwiklabs.net') GROUP BY 1,2,3,4,5,6,7,8 ORDER BY date DESC # latest transactions LIMIT 10;
- How to view a “view”:
-
#standardSQL SELECT * FROM ecommerce.vw_large_transactions;
- Ingesting type as ingesting a new “dataset”:
- EL (extract-load)
- ELT (extract-load-transform)
-
ETL (extract-transform-load)
- Small transformation can be done simply by a SQL. But it’s too large, just use ETL services: Cloud data Fusion, Dataflow, Dataproc.
- BigQuery can query external data sources in Cloud Storage or Drive directly.
- We can stream records into BigQuery.
- External data Sources:
- Data in different Cloud database.
- There are 2 mechanisms to query external data: “federated queries” & “external tables”.
-

- Note, we even can access data in “AWS buckets” or “Azure blob storage”.
- LAB(1 credit): Ingesting New Datasets into BigQuery
- Task 1. Create a new dataset to store tables: btn ⋮
- Task 2. Ingest a new Dataset from a CSV
- Upload a file from local machine into BigQuery Storage.
- click dataset ⋮ => “create table”
- Always check “Auto Detect” for Schema
- Task 3. Ingest data from Cloud Storage (Bucket list)
- click dataset ⋮ => Create table from: Google Cloud Storage
- In the Create table form, on “Advanced options” and in the “Write preference” dropdown menu, select “Overwrite table”.
-
Task 4. Ingest a new dataset from a Google Spreadsheet
- Task 5. Saving data to Google Sheets
- run a SQL query, get a result => press btn “SAVE RESULTS” in BigQuery window => choose “GOOGLE SHEETS”
- after saving, open it.
- modify the table with some “comments”
- Back to BigQuery, select “create table” => Create table from: Drive => copy and paste the shared-url of the table in google sheet into “Select Drive Uri” =>